Markov Chains
March 2, 2003
A Markov chain, as I understand it, is a graph that carries probabilities in its edges. If you’re at a node, the directed edges will tell you the probability of going to each of your neighbors.
The best-known application of this is to generate random text. Load a text file one character at a time and create a node in your graph for each unique letter you see. If you just loaded letter x and now read letter y, add a directed edge from node x to node y. If the edge already exists, increment the count associated with it. At the end you’ll have a graph that encodes each letter pairs and their frequency of occurrence. (You can think of normalizing each node’s outgoing edges so that those numbers represent probabilities of going to each of its neighbors, and the sum of each node’s outgoing edges is one.)
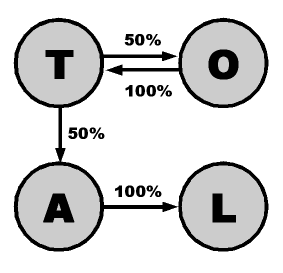
For example, with the input string TOTAL you’d generate a graph with four nodes (T, O, A, L). The T node would have two edges (probability 50% each), one to O and one to A. O would have a single edge to T, A only to L, and L would have no outgoing edges. You could then create text by traveling through this graph, following edges according to their probabilities. The output would sound a lot like the input, and the more input you had the more varied the output would be.
It’s more interesting when each node represents an N-letter prefix. (In the example above, N = 1.) The longer the prefix, the more natural the output sounds, until the prefix is so long that the output is virtually identical to the input. So when N is 1, the output is faithful in its two-letter pair frequencies (“q” is almost always followed by “u”), but it doesn’t resemble a natural language. When N is 3 or 4, most words become recognizable, though long words will often get grafted together and you’ll see things like “therefortunate”. When N is 10 the output will usually be complete sentences that mostly make sense. The larger the input file, the greater variety in the output.
The output when N is around 3 or 4 can be pretty funny, like this output based on the previous paragraph (N = 4):
My friend Cassidy Curtis had the great idea of generating two Markov chains from two very different sources (say from two languages) and interpolating between the two graphs, and I wrote a program in Java to do this. The greater the contrast in the input files, the more striking the result. This is a sample from interpolating between Genesis in English and Genesis in Spanish (N = 1):
N = 2:
N = 3:
N = 4:
It’s actually quite hard to get a good interpolation with different languages. If N is too small then the output is gibberish, and if it’s too large then it is difficult to switch to the other language. I have found that the chain will switch more easily from English to Spanish than the other way. I don’t know why.
Here’s another paragraph with the Spanish letters highlighted in red:
The way I interpolate is as follows: Given a prefix, I get the next letter using both chains. I then use an interpolating factor to choose randomly between the two. (If only one of the chains gave me a letter, then I choose that one regardless.) In the above examples the interpolating factor went from 0.0 to 1.0 in 1/300 increments, giving me a paragraph of about 300 letters.
Evidently the second example above got stuck in English at the end despite the interpolant being at almost 1.0 (Spanish).
That may not be a good way to interpolate, though. It may work better to blend the two Markov chains into one, keeping track of which chain each edge came from. You’d have to somehow dynamically change the probabilities as the interpolating factor changed. I’m not convinced that this is any different than my scheme.
The program gets less stuck if you use two very different sources in the same language. For example, an excerpt from the Bible and some erotica. The program can generate phrases that are more blasphemous than you can imagine.
You can download the source code in Java. Please let me know if you modify it. It’s called “A” for historical reasons: The first Markov chain program I wrote 10 years ago was called “a” because I understood the concepts but couldn’t remember the name “Markov”. A lot of people saw it and have referred to it as “your ‘a’ program” since then, so this new version kept the name.