One of the central assumptions about our asynchronous system is that we cannot detect the death of a process, and therefore we cannot distinguish a dead process from a merely slow one. Therefore, simply adding failure detectors would solve our problem without relaxing either our definition of consensus or our assumptions about the asynchrony in the underlying system.
We can imagine a module which is a failure detector for the system. This module could keep a list of processes which it thinks has crashed, and could regularly probe each process to update its list. Since this failure detector cannot be sure of a process death any more than any other process can, we should assume that it will not only make mistakes, but will make an infinite number of mistakes. The weakest properties that this module could have would be (1) all fail-stop processes are eventually detected, and (2) some correct process which is on the list of failed processes should eventually be taken off the list.
This can be implemented in practice by having the failure
detector probe each process regularly; an unresponsive process p
is placed on the list and a broadcast message is sent to
all processes (including p) announcing its death. If p
is has not actually crashed, then it will eventually refute
its death announcement. Chandra and Toueg [5] show
that this weak and unreliable model of failure detectors
allows the consensus problem to be solved. The failure detector
described above requires 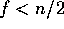 , where f is the actual
number of failures and n is the total number of processes.
In [4], Chandra et al. prove that this
failure detector is indeed the weakest that can solve
the consensus problem.
A stronger model of failure detectors allows f < n, although
it may be difficult to implement in practice
because it requires that at least one correct process is
never suspected of being faulty.
, where f is the actual
number of failures and n is the total number of processes.
In [4], Chandra et al. prove that this
failure detector is indeed the weakest that can solve
the consensus problem.
A stronger model of failure detectors allows f < n, although
it may be difficult to implement in practice
because it requires that at least one correct process is
never suspected of being faulty.